
◎FizzBuzz問題とは?
数字を1から順に言っていき、3の倍数の時はFizz、5の倍数の時はBuzz、3の倍数かつ5の倍数の時はFizzBuzzと代わりに言う英語圏における言葉遊び。
DeepLearningを勉強し始めた当時、脳死でFizzBuzz問題を解いたときの失敗の話です。
結論、先にいいます。
・脳死でなんでもできるほどDeepLearningは万能ではない
・データの特徴量は超重要
— ここから本編 —
FizzBuzz問題は”Hello, World”に並ぶプログラミング初心者向けの問題で、pythonでコード実装すると↓みたいに書けますね。
|
1 2 3 4 5 6 7 8 9 |
for i in range(1, 30): if i%15==0: print("FizzBuzz") elif i%5==0: print("Buzz") elif i%3==0: print("Fizz") else: print(i) |
実行結果
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
1 2 Fizz 4 Buzz Fizz 7 8 Fizz Buzz 11 Fizz 13 14 FizzBuzz 16 17 Fizz 19 Buzz Fizz 22 23 Fizz Buzz 26 Fizz 28 29 |
これをDeepLearningで解くために考えたモデルは↓みたいな感じ。(ここで、隠れ層4層からがDeepだとかいう議論は置いておきます。)
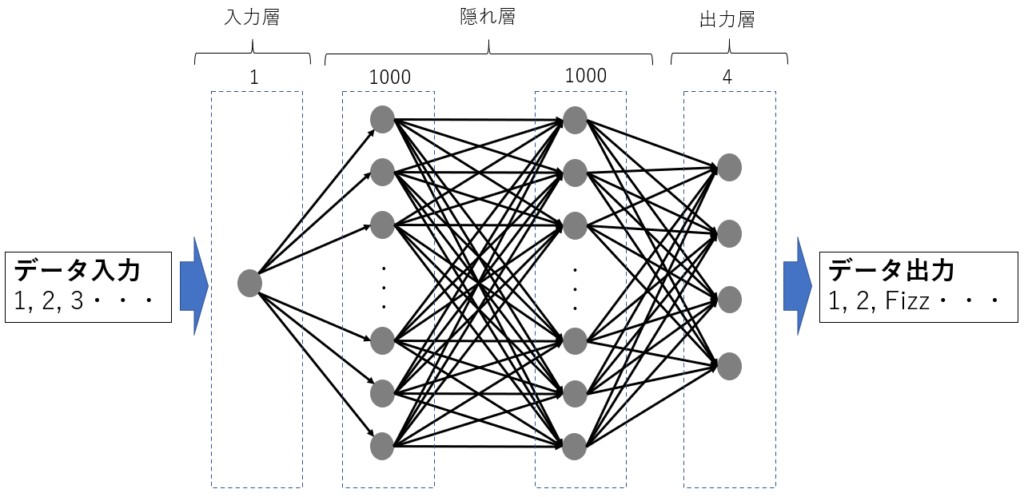
で
↓のようなコードにして学習させました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import numpy as np from keras.models import Sequential from keras.layers import Dense from keras.utils import np_utils from keras.layers import Dense from keras.models import Model def fizz_buzz_encode(i): if i % 15 == 0: return np.array([0, 0, 0, 1]) elif i % 5 == 0: return np.array([0, 0, 1, 0]) elif i % 3 == 0: return np.array([0, 1, 0, 0]) else: return np.array([1, 0, 0, 0]) NUM_DIGITS = 10 # TrainData( 200~1023 ) trainX = np.array([i for i in range(200, 2 ** NUM_DIGITS)]) trainY = np.array([fizz_buzz_encode(i) for i in range(200, 2 ** NUM_DIGITS)]) # ValidationData( 16~199 ) validationX = np.array([i for i in range(16, 200)]) validationY = np.array([fizz_buzz_encode(i) for i in range(16, 200)]) EPOCH = 500 model = Sequential() model.add(Dense(1000, input_dim=1, activation="relu")) model.add(Dense(1000, activation="relu")) model.add(Dense(4, activation="softmax")) model.compile(loss='categorical_crossentropy', optimizer='adagrad', metrics=["accuracy"]) result = model.fit(trainX, trainY, epochs=EPOCH, batch_size=128, verbose=1, validation_data=(validationX, validationY)) |
実行結果
|
1 2 3 4 5 6 7 8 9 10 11 |
Epoch 1/500 824/824 [==============================] - 3s 4ms/step - loss: 8.7193 - acc: 0.4551 - val_loss: 7.4459 - val_acc: 0.5380 Epoch 2/500 824/824 [==============================] - 0s 23us/step - loss: 7.5309 - acc: 0.5328 - val_loss: 7.4459 - val_acc: 0.5380 ・・・ Epoch 499/500 824/824 [==============================] - 0s 25us/step - loss: 7.5309 - acc: 0.5328 - val_loss: 7.4459 - val_acc: 0.5380 Epoch 500/500 824/824 [==============================] - 0s 27us/step - loss: 7.5309 - acc: 0.5328 - val_loss: 7.4459 - val_acc: 0.5380 |
・・・ん?
acc = 正解率 が53%のまま。学習していない、、だと。。。
一応グラフにして確認します。
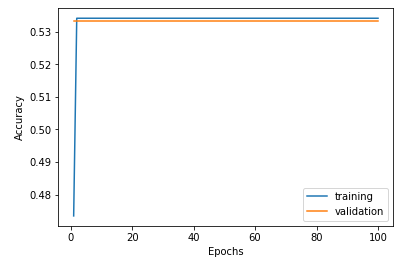
縦軸がAccuracy(正解率)、横軸がEpoch(学習回数)です。
右に行くほど学習回数が増え、正解率が上がる右肩上がりのグラフになるのが理想ですが、、、

い、一応テストデータで検証してみますか・・・
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# TestData( 1~15 ) testX = np.array([i for i in range(1, 16)]) # Prediction pred = model.predict_classes(testX) def fizz_buzz_echo(num, categoly): if categoly ==3 :return ("FizzBuzz!") if categoly ==2 :return ("Buzz!") if categoly ==1 :return ("Fizz!") if categoly ==0 :return (str(num)) for i in testX: print(fizz_buzz_echo(i, pred[i-1]) ) |
実行結果
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
1 2 3 ← Fizzが正解 4 5 ← Buzzが正解 6 ← Fizzが正解 7 8 9 ← Fizzが正解 10 ← Buzzが正解 11 12 ← Fizzが正解 13 14 15 ← FizzBuzzが正解 |
なーーーーーーーーーーーんもできるようになってないじゃん
色々記事を漁ってみて、こちらの記事にたどり着きました。https://qiita.com/cvusk/items/07659830c41b2c3ff02b(Kerasでfizzbuzz問題を解いてみる)
こちらの方のモデルを図にすると↓です。
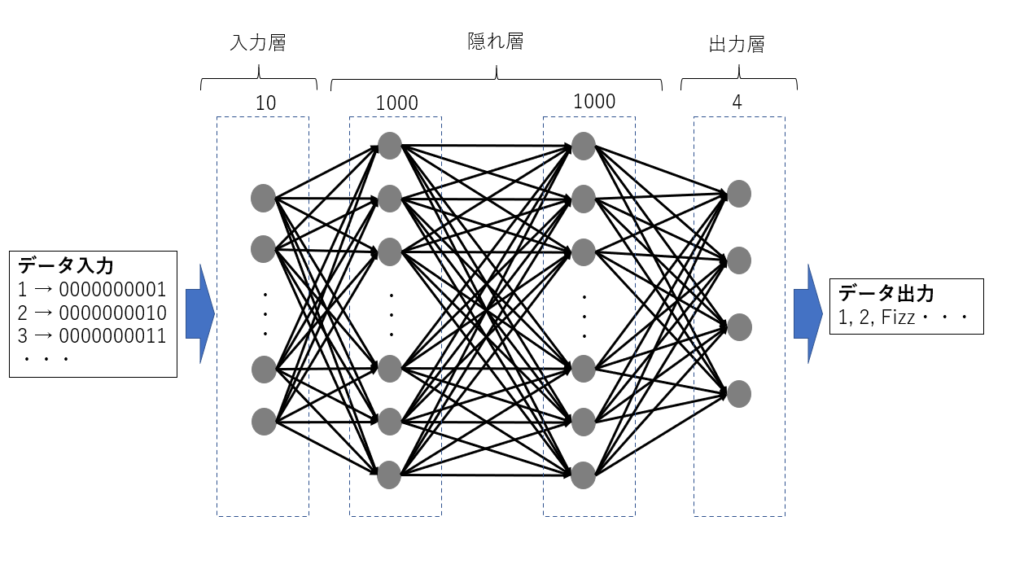
数字を2進数に変換してモデルに入力しています。なるほど。。。。
ここでやっと自分の愚かさに気づきました。”数字の特徴”を捉えているものを入力データとしなければいけないことを。。。
例えば、12という数字には↓のように様々な表現がありますね。
・10^1+2×10^0 (10進数表現 )
・1×2^3+1×2^2 ( 2進数表現 )
私が最初に作ったモデルの入力データはいうなれば、1桁のn進数です。
学習するには情報が少なすぎる不親切な入力データなのかもしれませんね。
さてさて間違いに気づいたところで、いざ実装。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import numpy as np from keras.models import Sequential from keras.layers import Dense from keras.utils import np_utils from keras.layers import Dense from keras.models import Model def fizz_buzz_encode(i): if i % 15 == 0: return np.array([0, 0, 0, 1]) elif i % 5 == 0: return np.array([0, 0, 1, 0]) elif i % 3 == 0: return np.array([0, 1, 0, 0]) else: return np.array([1, 0, 0, 0]) def binary_encode(i, num_digits): return np.array([i >> d & 1 for d in range(num_digits)]) NUM_DIGITS = 10 # TrainData( 200~1023 ) trainX = np.array([binary_encode(i, NUM_DIGITS) for i in range(200, 2 ** NUM_DIGITS)]) trainY = np.array([fizz_buzz_encode(i) for i in range(200, 2 ** NUM_DIGITS)]) # ValidationData( 16~199 ) validationX = np.array([binary_encode(i, NUM_DIGITS) for i in range(16, 200)]) validationY = np.array([fizz_buzz_encode(i) for i in range(16, 200)]) EPOCH = 500 model = Sequential() model.add(Dense(100, input_dim=NUM_DIGITS, activation="relu")) model.add(Dense(100, activation="relu")) model.add(Dense(4, activation="softmax")) model.compile(loss='categorical_crossentropy', optimizer='adagrad', metrics=["accuracy"]) result = model.fit(trainX, trainY, epochs=EPOCH, batch_size=64, verbose=1, validation_data=(validationX, validationY)) |
zik
|
1 2 3 4 5 6 7 8 9 |
Epoch 1/500 824/824 [==============================] - 0s 583us/step - loss: 1.1897 - acc: 0.5303 - val_loss: 1.1700 - val_acc: 0.5380 Epoch 2/500 824/824 [==============================] - 0s 38us/step - loss: 1.1499 - acc: 0.5328 - val_loss: 1.1490 - val_acc: 0.5380 ・・・ Epoch 499/500 824/824 [==============================] - 0s 38us/step - loss: 0.0764 - acc: 0.9964 - val_loss: 0.5162 - val_acc: 0.8152 Epoch 500/500 824/824 [==============================] - 0s 36us/step - loss: 0.0765 - acc: 0.9964 - val_loss: 0.5086 - val_acc: 0.8207 |
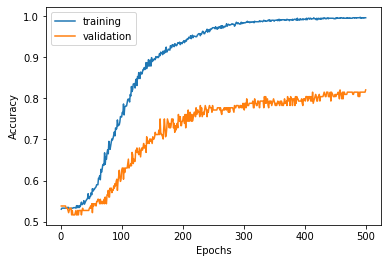
はい。ちゃんと学習しているようですね。
テストデータで確認してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# TestData( 1~15) testX = np.array([binary_encode(i, NUM_DIGITS) for i in range(1, 16)]) # Prediction pred = model.predict_classes(testX) def fizz_buzz_echo(num, categoly_num): if categoly_num ==3 :return ("FizzBuzz!") if categoly_num ==2 :return ("Buzz!") if categoly_num ==1 :return ("Fizz!") if categoly_num ==0 :return (str(num)) for i in range(1, 16): print(fizz_buzz_echo(i, pred[i-1]) ) |
実行結果
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
1 2 Fizz! 4 5 ←Buzzが正解 Fizz! 7 8 Fizz! Buzz! 11 12 ←Fizzが正解 13 14 15 ←FizzBuzzが正解 |
おお!全問正解とはいきませんでしたが、ちゃんと学習していそうです。
ここから精度を上げるためには、ハイパーパラメータのチューニングやらモデルの初期値やら学習回数やら学習データを増やしたりやら、、、色々やり方はありそうですがその辺はまた後で。
以上です。


コメント