gymの自作環境の作り方が分かったので、fx攻略してみた。
結論は失敗でした。まあ、モデルから環境から学習データから何から何まで改良の余地がありそうなので、また近いうちにトライしてみようと思います。
そりゃ機械学習の知識が皆無のシロウトが適当に用意した学習データと適当に組んだモデルで世界最大のマネーゲームを攻略できたら、世の中金持ちだらけですね。
まあ、せっかく作ったのだから、記事にしておこうと思います。
まず、こちらが今回の学習データ(兼テストデータ)。20181016の0:10~8:29のドル/円です。
上が1分足終値で、下が出来高です。 (強化学習でエージェントが観測できる値は、この2つに加えて”1分足始値”・”1分足最低値”・”1分足最高値”の全部で5つとしました。)
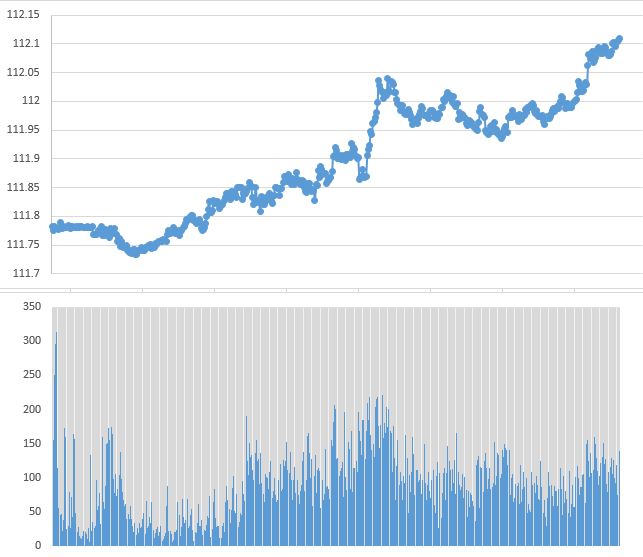
また、なぜたった8時間という短い期間のデータを使ったかというと、
・学習時間を短縮したかったから
・期間が短いほど、テクニカル分析が重要だから(期間が長いと経済指標やニュースなどのファンダ分析が重要になる)
Q値学習のためのモデルにはLSTM(Long short-term memory )を使いました。
LSTMはRNNの仲間の一つで時系列データの学習に有効らしいです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
model = Sequential() model.add(Flatten(input_shape=(1,) + env_train.observation_space.shape)) model.add(Dense(16)) model.add(Activation('relu')) model.add(Dense(16)) model.add(Activation('relu')) model.add(Dense(16)) model.add(Activation('relu')) model.add(Reshape((16, 1), input_shape=(16, ))) model.add(LSTM(50, input_shape=(16, 1), return_sequences=False, dropout=0.0)) model.add(Dense(nb_actions)) model.add(Activation('linear')) print(model.summary()) |
エージェントの行動は、”買”, “売”, “ステイ”の3種類で、”買”, ”売”の注文量は一定(要は全力買/全力売)としました。また、エージェントは1分足の終わりに一回だけ行動できるものとしました。
|
1 2 3 4 5 6 7 |
# ②トレードアクション実行( buy, sell, stay ) if action == 0: self.trade_sys.order("BUY", rate, trade_system.AMOUNT_MAX) elif action == 1: self.trade_sys.order("SELL", rate, trade_system.AMOUNT_MAX) else: pass |
*ここに関して、自分がノーポジかロングポジやショートポジかでアクションの結果が変わってしまうのでこれであっているか分かりません。
エージェントへの報酬は、行動をとった1分後にどのくらい(確定損益+含み損益)が増えたか/減ったかとしました。
|
1 2 3 4 |
def _get_reward(self): # 報酬を返す。 reward = (self.trade_sys.profit - self.trade_sys.profit_pre) + (self.trade_sys.inprofit - self.trade_sys.inprofit_pre) return reward |
トレードシステムは、レバレッジ25倍・スプレッド0.005pips固定としました。
|
1 2 3 4 |
class trade_system(): def init(self): self.leverage = 25 # レバ25倍 self.spread = 0.005 # スプレッド固定 [pips] |
*スプレッドとは取引にかかる手数料のようなものです。これは本来、その時間帯の取引量などによって変動しますが、実装が面倒+計算式を知らないので固定にしました。
学習回数は10000ステップです。”0:10~8:29の500ステップ”を20回なのでかなり少なく感じますが、いい感じに学習してそうだったらステップ数を増やします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# Finally, we configure and compile our agent. You can use every built-in Keras optimizer and # even the metrics! memory = SequentialMemory(limit=10000, window_length=1) #policy = BoltzmannQPolicy() policy = EpsGreedyQPolicy(eps=0.1) dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=10, target_model_update=1e-2, policy=policy) dqn.compile(Adam(lr=1e-3), metrics=['mae']) # Okay, now it's time to learn something! We visualize the training here for show, but this # slows down training quite a lot. You can always safely abort the training prematurely using # Ctrl + C. dqn.fit(env_train, nb_steps=10000, visualize=True, verbose=2) |
結果、、、、
終値と含み益が同じように上がっていき、確定利益はずっと0のままです。
つまり、”最初に買いを入れてずっと放置”という戦略をAIは立てたようです。
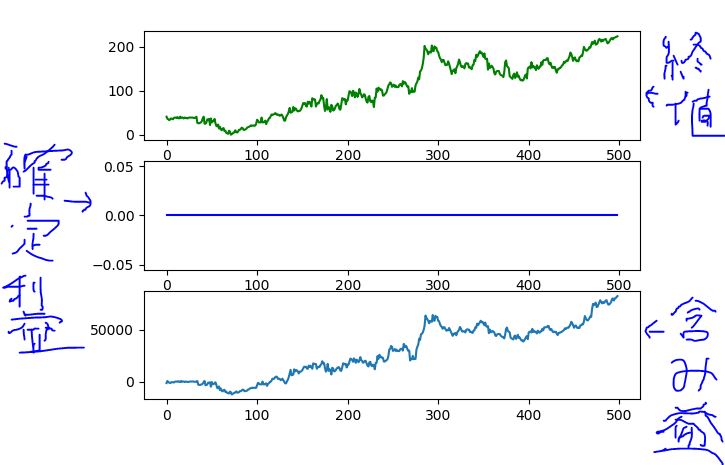
スプレッドがあるせいで、取引回数が多い = 損 ということを学んだのかと思い、スプレッドを0にして再度試してみましたが、結果は変わりませんでした。
コードはgithubに上げておきました。


コメント