
前回作ったゲーム環境を、僕の考えた最強のAI()を作って攻略していきたいと思います。
まずはgymに自作の環境を登録します。
battle\__init__.py
\env.py ←前回作ったファイル
__init__.pyを作っておくと、gym.make(‘id’)で自作の環境を呼び出すことができます。
( id= <環境名>-v<バージョン>, entry_point = <フォルダ名>.<env>:<class名> という形式で定義します )
__init__.py
|
1 2 3 4 5 6 |
from gym.envs.registration import register register( id='battle-v0', entry_point='battle.env:battle' ) |
次にKeras-RLをインストールします。
|
1 |
$ git clone https://github.com/matthiasplappert/keras-rl.git<br />$ python keras-rl/setup.py install |
keras-rl/examples/ 以下のファイルを参考に、自作環境を攻略するAI(強化学習ではエージェントという)を定義します。
今回、Q値予測のモデルにはDNNを使いました。
Q値というのは、現在の環境における各行動の期待値のようなものです。AIは実際に行動した結果から、このQ値を学習していきます。
dqn_battle.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
import battle import numpy as np import gym from keras.models import Sequential from keras.layers import Dense, Activation, Flatten, LSTM, Reshape from keras.optimizers import Adam from rl.agents.dqn import DQNAgent from rl.policy import BoltzmannQPolicy from rl.policy import EpsGreedyQPolicy from rl.memory import SequentialMemory ENV_NAME = 'battle-v0' # Get the environment and extract the number of actions. env = gym.make(ENV_NAME) np.random.seed(123) env.seed(123) nb_actions = env.action_space.n # Next, we build a very simple model. model = Sequential() model.add(Flatten(input_shape=(1,) + env.observation_space.shape)) model.add(Dense(2)) model.add(Activation('relu')) model.add(Dense(2)) model.add(Activation('relu')) model.add(Dense(2)) model.add(Activation('relu')) model.add(Dense(nb_actions)) model.add(Activation('linear')) print(model.summary()) # Finally, we configure and compile our agent. You can use every built-in Keras optimizer and # even the metrics! memory = SequentialMemory(limit=50000, window_length=1) policy = BoltzmannQPolicy() dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=10, target_model_update=1e-2, policy=policy) dqn.compile(Adam(lr=1e-3), metrics=['mae']) # Okay, now it's time to learn something! We visualize the training here for show, but this # slows down training quite a lot. You can always safely abort the training prematurely using # Ctrl + C. dqn.fit(env, nb_steps=50000, visualize=True, verbose=2) # After training is done, we save the final weights. dqn.save_weights('dqn_{}_weights.h5f'.format(ENV_NAME), overwrite=True) # Finally, evaluate our algorithm for 5 episodes. dqn.test(env, nb_episodes=5, visualize=True) |
①結果(DNN)
50000回学習させた結果、3ターンで死亡するAIが出来上がりました。なんでだろ(´・ω・`)
学習の中で、BOSSを倒す経験もできていたのですが、上手くいかなかった。。。
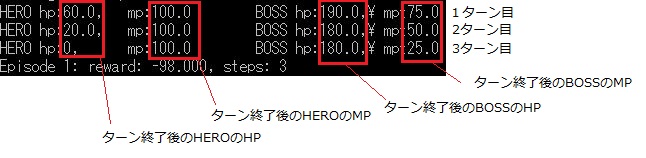
勝った時の報酬が足りないのかなと思い、報酬の与え方とかいろいろ変えてみましたが、上手くいきません。そこでQ値のモデルをLSTMに変更してみることに。(今後使おうと思っていたので、ノリで使ってみました。)
↓
|
1 2 3 4 5 6 7 8 |
model = Sequential() model.add(Flatten(input_shape=(1,) + env.observation_space.shape)) model.add(Reshape((2, 1), input_shape=(2, ))) model.add(LSTM(50, input_shape=(2, 1), return_sequences=False, dropout=0.0)) model.add(Dense(nb_actions)) model.add(Activation('linear')) |
②結果(LSTM)
同様に50000回学習させた結果、倒せた!( ;∀;)
序盤に無駄に回復呪文を使っているため、倒すまで37ターンと結構時間がかかっていますが、途中で回復を挟みながら戦うことでBOSSを倒すことに成功しています。
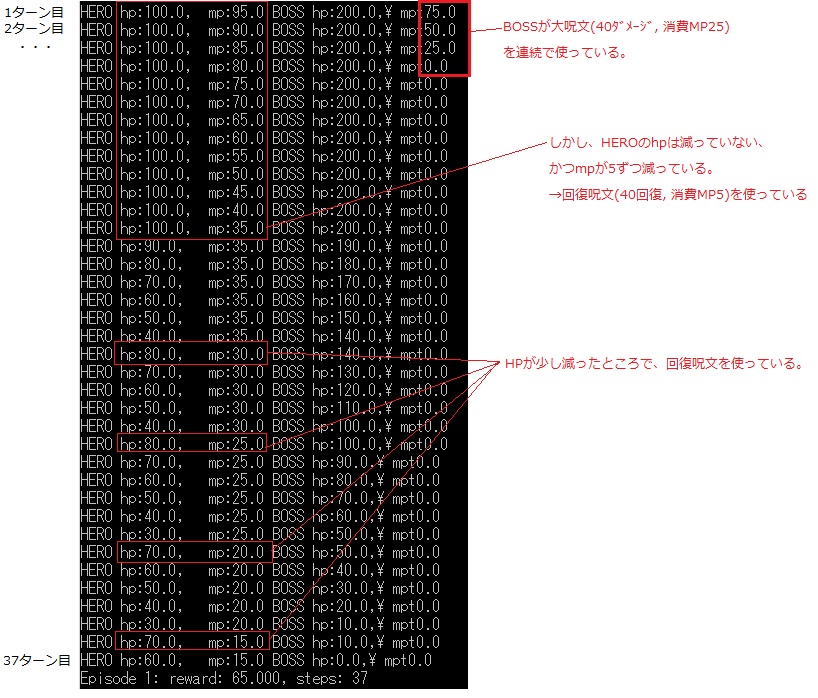
今回、エージェントにはBOSSのHP, MPが見えない状態で学習させていました。(ドラ○エも敵のHP, MPは見えないので)
DNNモデルのAIには、HEROのHP, MPだけでは、情報が少なすぎたのかも。
LSTMモデルのAIは、前の観測値も参照できるので、戦闘の前半は回復多め、後半は回復少なめ、といった時間軸に沿った戦い方を学んだのかもしれません。
==================
↓普段の食事で足りない栄養を補えるおいしいグミ。 ホントにおすすめです。
コメント